
Paper Reviews
Published:
Motivation
As I step into this world of research, I realised I’m still in the midst of discovering what I’m truly interested in. To this end, I hope to read papers solely because I’m interested in it (instead of, say, to do literature review for my current research).
From a professional standpoint, I hope for this consistency pays off in terms of ideating my own novel ideas, inspired by the ideas from the community.
Paper Reviews
Papers which I enjoyed are in bold or prepended with [F].
July
Unsupervised Text Style Transfer using Language Models as Discriminators, NeurIPS2018
- encoder-decoder architecture with style discriminators to learn disentangled representations. The encoder takes a sentence as an input and outputs a style-independent content representation. The style-dependent decoder takes the content representation and a style representation and generates the transferred sentence.
- Shen et al. (2017) leverage an adversarial training scheme where a binary CNN-based discriminator is used to evaluate whether a transferred sentence is real or fake, ensuring that transferred sentences match real sentences in terms of target style.
- However, in practice, the error signal from a binary classifier is sometimes insufficient to train the generator to produce fluent language, and optimization can be unstable as a result of the adversarial training step
- This paper proposes to replace the binary CNN-based discriminator with language models
[F]On Variational Learning of Controllable Representations for Text without Supervision, ICML2020
- Problem. For VAEs => manipulate latent factors (cuz of TST) lead to sampling from low density regions of the aggregated posterior distributions. In other words, there are vacant regions in the latent code space. As a result, the decoding network is unable to process such manipulated latent codes.
- Proposed to constrain the posterior mean to a learned probability simplex and only perform manipulation within this simplex.
- Two regularizers are added to the original objective of VAE. The first enforces an orthogonal structure of the learned probability simplex; the other en- courages this simplex to be filled without holes.
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?, ACL 2022
- In-Context Learning.
- Perform a new task via inference alone by conditioning on a few input-label pairs (demonstrations) and making predictions for new inputs.
- Here, conditioning can be as simply as concatenating the training data as demonstrations
- Important to note that there are no gradient updates; ICL is done during inference only.
- Motivation for ICL.
- Might not have resources to train model (e.g. finetuning), especially since models are getting too big
- API might only support inference.
- This paper found that replacing the labels in demonstrations with random labels barely hurts performance. It’s counterintuitive that the model does not rely on the input-label mapping to perform the task.
- Instead, the paper found that the label space, distributions of the input text, overall format is more important in ICL working.
- Meta-training with an in-context learning objective magnifies these effects

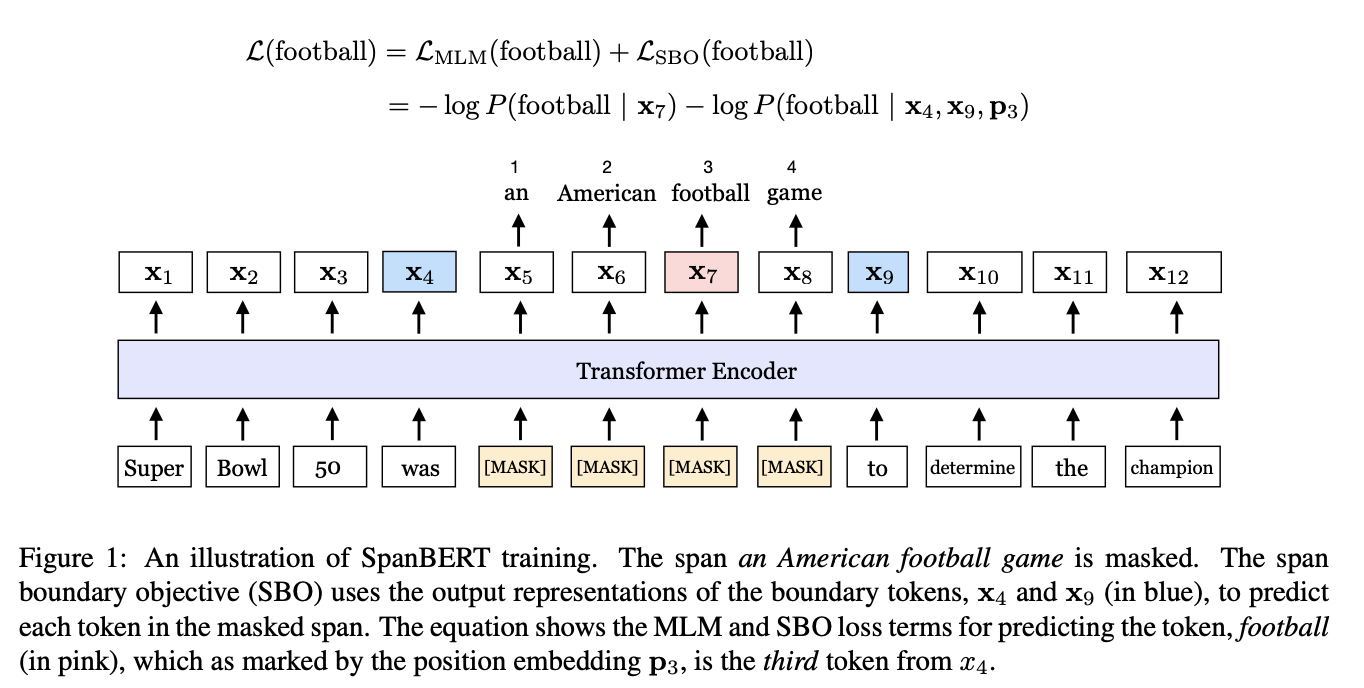
- Motivation. Many NLP tasks involve reasoning about relationships between two or more spans of text. For example in extractive QA, determining that the “Dever Broncos” is a type of “NFL team” is critical for answering the question “Which NFL team won Super Bowl”.
- We present SpanBERT, a pre-training method that is designed to better represent and predict spans of text.
- Mask random contiguous spans rather than random individual tokens
- Introduce a novel span-boundary objective so the model learns to predict the entire masked span from the observed tokens at its boundary.Span-based masking forces the model to predict entire spans solely using the context in which they appear. Furthermore, the span-boundary objective encourages the model to store this span-level in- formation at the boundary tokens, which can be easily accessed during the fine-tuning stage.
June
- Problem. Supervised approaches for TST shows impressive generation quality, but parallel samples are often unavailable. RL is introduced to develop unsupervised models such that the rewards of content preservation and style conversion are used to optimize seq. generation. However, RL-based methods are often challenging to train in practice. For in- stance, the rewards have high variance during early stages when learning from scratch, which affects the training stability; and they cannot provide fine- grained learning signals as traditional token-level maximum likelihood estimation, since they are of- ten calculated on the entire generated sequence
- Proposed a semi-supervised frame- work for text style transfer, and optimize it on training stability and signal fineness
- First trains model on small amount of parallel data for supervised learning.
- Bootstraps the training process with automatically consructed pseudo parallel data. Two pseudo pair matching methods are investigated: a lexical-based strategy, which is straightforward by calculating the token-level overlap; and a semantic-based strat- egy, which uses semantic similarity as criteria and would have better general potential.
- Furthermore, to obtain fine-grained signals for the RL-based sequence-to-sequence training pro- cess, we propose a stepwise reward re-weighting strategy. This is inspired by the observation that the style transfer weights are not uniform across tokens/spans in the source sentence: some tokens weigh more during attribute-guided text style trans- fer (Li et al., 2018). Therefore, instead of using the reward (e.g., style strength scores) calculated from the entire generated sentence (Luo et al., 2019; Lai et al., 2021), we use the token-level reward. Specifically, we extract attribute-related attentive scores from a pre-trained style discriminator, obtain a stepwise reward by re-weighting the sequence- level score, and utilize it as a fine-grained signal for policy gradient back-propagation.
- Attribute-related attentive scores refer to how attention weights correlate strongly with salient tokens (at least, based off their empirical observation). Thus they reweight the sequence-level reward with the stepwise scores.
- Reinforcement Learning. Uses two rewards to enhance style rewriting and content preservation.
- Reconstruction reward. Backtranslated output to improve content preservation.
where $x$ is the backward target, $G(\hat{y})$ is the back translated output from greedy decoding generation $\hat{y}$ and $G(y’)$ back-translated from sampling-based generation $y’$ over a multi-nominal distribution. BLEU is used for the score function.
- Style classification reward. Used a Transformer model trained for binary style classification to evaluate how well the transferred sentence y’ matches the target style.
- The reward-based learning is conducted via Policy Gradient back-propagation.
Image Style Transfer using CNNs
- Motivation. Most non-parametric algorithms only use low-level image features of the target image to inform the texture transfer.
- Key Idea.
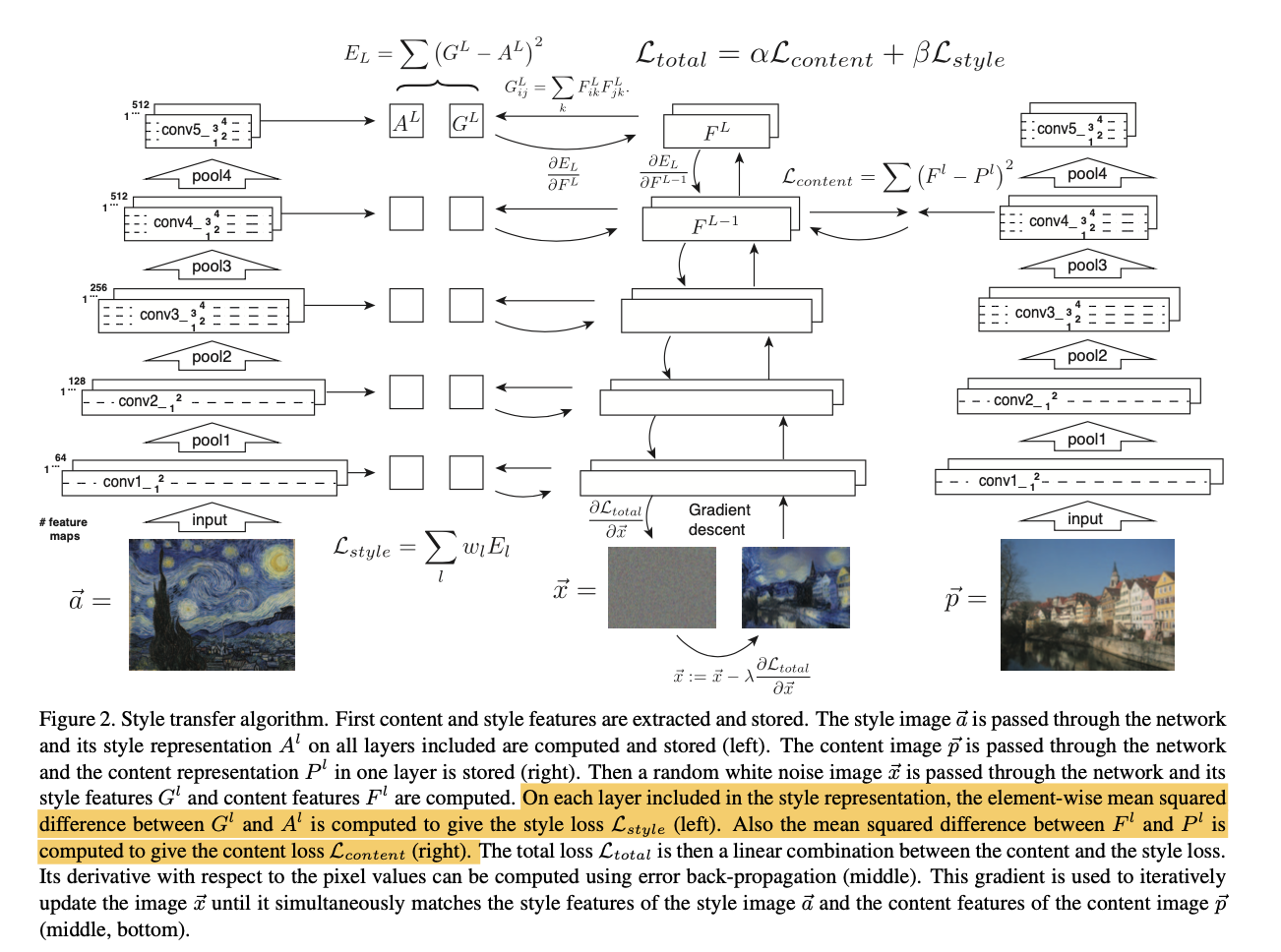
- Texture transfer algorithm that constraints a texture synthesis methods by feature representations from CNNs. The feature representations of the CNNs are first analysed in figure 1.
- To visualize the image information that is encoded at different layers of the hierarchy, one performs gradient descent on a white noise image to find another image that matches the feature responses of the original image. That is, we change the original white noise image such that the feature representations in the particular layer of the CNN matches that (feature repr in the particular layer) of the original image.
- The process is similar for the style reconstruction. However, instead of matching the feature responses, we match the feature correlations between different feature responses. Specifically, the feature correlations are given by the gram matrix between the vectorised feature maps i and j in layer l.
- To transfer the style of an artwork onto a photograph we synthesise a new image that simultaneously matches the content representation of p and the style representation of a (Fig 2). Thus we jointly minimise the distance of the feature representations of a white noise image from the content representation of the photograph in one layer (the top layer, since it captures high-level information) and the style representation of the painting defined on a number of layers of the Convolutional Neural Network.
- Texture transfer algorithm that constraints a texture synthesis methods by feature representations from CNNs. The feature representations of the CNNs are first analysed in figure 1.

[F]Longformer: The Long-Document Transformer
- Problem. Memory and computational reqs of self attention grows quadratically with sequence length, making it infeasible to process long sequences.
- To address this limitation, we present Long- former, a modified Transformer architecture with a self-attention operation that scales linearly with the sequence length, making it versatile for processing long documents.
- Longformer’s attention mechanism is a combination of a windowed local-context self-attention and an end task motivated global attention that encodes inductive bias about the task. Through ablations and controlled trials we show both attention types are essential – the local attention is primarily used to build contextual representations, while the global attention allows Longformer to build full sequence representations for prediction.
- WRT to figure 2, the local attention takes the form of the sliding window attention. Observe that each token only attends to a window of tokens surrounding it (as opposed to every other tokens)
- The global attention are pre-selected input locations which attends to all tokens across the sequence, and all tokens in the sequence attend to it. For example, the CLS token is selected for classification tasks.
[F]Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
- Most works tackle the lack of parallel corpus by separating the content from the style of the text. Thereafter, it encodes sentences to style-independent representations, then uses a generator to combine the content with style.
- However, these approaches are limited by their use of loss functions that must be differentiable with respect to the model parameters, since they rely on gra- dient descent to update the parameters. As such, they typically focus only on semantic and style metrics (which are differentiable). This is an important limitations because there are other non-differentiable metrics such as language fluency.
- This work proposed a RL approach to TST. Key advantage of using RL is that they can use non-differentiable metrics to account for the quality of transferred sentences.
Reinforcement Learning
- The generator G is parameterized with a parameter set $\theta$, and we defined the expected reward of the current generator as $J(G_{\theta})$. The total expected reward is
where $P_{\theta} (y_t | s_t)$ is the likelihood of word $y_t$ given the current state $s_t$ and $Q({s_t, y_t})$ is the cumulative rewards that evaluate the quality of the sentences extended from $Y_{1:t}$.
- The key is in the total reward $Q$, which is defined as the sum of the word rewards
where $r(s_t, y_t)$ is the reward of word $y_t$ at state $s_t$, $\gamma$ is the discounting factor so that the future rewards have decreasing weights since their estimates are less accurate.
- By design, the non-differentiable evaluation modules only evaluate complete sentences instead of single words or partial sentences. Thus, we cannot obtain $r(s_t, y_t)$ directly from the evaluation modules at any time instance before the end of the sentence. To circumvent this, the paper uses roll out: the generator rolls out the given sub sentence $Y_{1:t}$ at time step $t$ to generate the complete sentences by sampling the remaining part of the sentence ${Y_{t+1:T’}^n}$.
- They score the action $y_t$ at state $s_t$ by the average score of the complete sentences rolled out from $Y_{1:t}$.
Unsupervised Text Style Transfer using Language Models as Discriminators
- Previous work on unsupervised TST adotps an encoder-decoder architecture with style discriminators to learn disentangled representations. The encoder takes a sentence as an input and outputs a style-independent content representation. The style-dependent decoder takes the content representation and a style representation and generates the transferred sentence.
For example, Shen et al. (2017) leverage an adversarial training scheme where a binary CNN-based discriminator is used to evaluate whether a transferred sentence is real or fake, ensuring that transferred sentences match real sentences in terms of target style.
- However, in practice, the error signal from a binary classifier is sometimes insufficient to train the generator to produce fluent language, and optimization can be unstable as a result of the adversarial training step.
- We propose to use an implicitly trained language model as a new type of discriminator, replacing the more conventional binary classifier.
- The language model calculates a sentence’s likelihood, which decomposes into a product of token-level conditional probabilities.
- In our approach, rather than training a binary classifier to distinguish real and fake sentences, we train the language model to assign a high probability to real sentences and train the generator to produce sentences with high probability under the language model.
- Because the language model scores sentences directly using a product of locally normalized probabilities, it may offer more stable and more useful training signal to the generator. Further, by using a continuous approximation of discrete sampling under the generator, our model can be trained using back-propagation in an end-to-end fashion.
[F]Style Transfer from Non-Parallel Text by Cross-Alignment
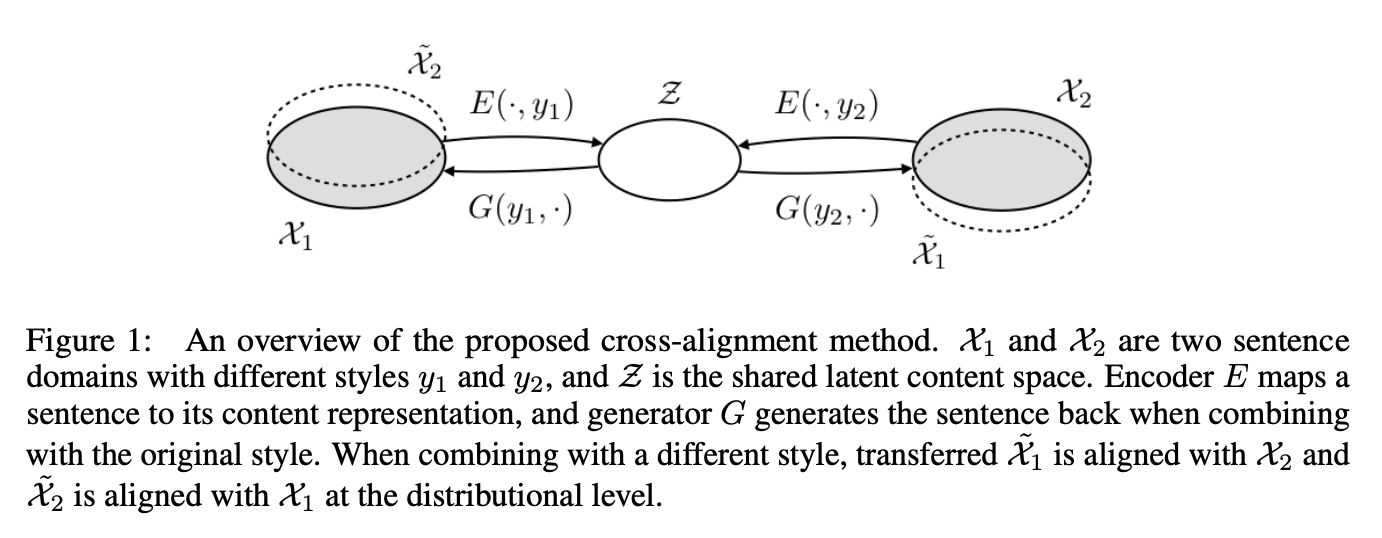
- Problem. TST with non-parallel text
- Key Ideas
- Assume a shared latent content distribution across different text corpora. This shared latent distribution connects the two corporas without having them to be parallel!
- Concretely, we learn an encoder that takes a sentence and its original style indicator as input, and maps it to a style-independent content representation. This is then passed to a style-dependent decoder for rendering (see figure below).
- Moreover, we reap additional information from cross-generated (style-transferred) sentences, thereby getting two distributional alignment constraints. For example, positive sentences that are style-transferred into negative sentences should match, as a population, the given set of negative sentences
RoBERTa: A Robustly Optimized BERT Pretraining Approach
- We present a replication study of BERT pre- training (Devlin et al., 2019), which includes a careful evaluation of the effects of hyperparmeter tuning and training set size.
- Our modifications are simple, they include: (1) training the model longer, with bigger batches, over more data; (2) removing the next sentence prediction objective; (3) training on longer se- quences; and (4) dynamically changing the masking pattern applied to the training data
- Collect a large new dataset (CC-News) of comparable size to other privately used datasets, to better control for training set size effects.
[F]Siamese Neural Networks for One-shot Image Recognition 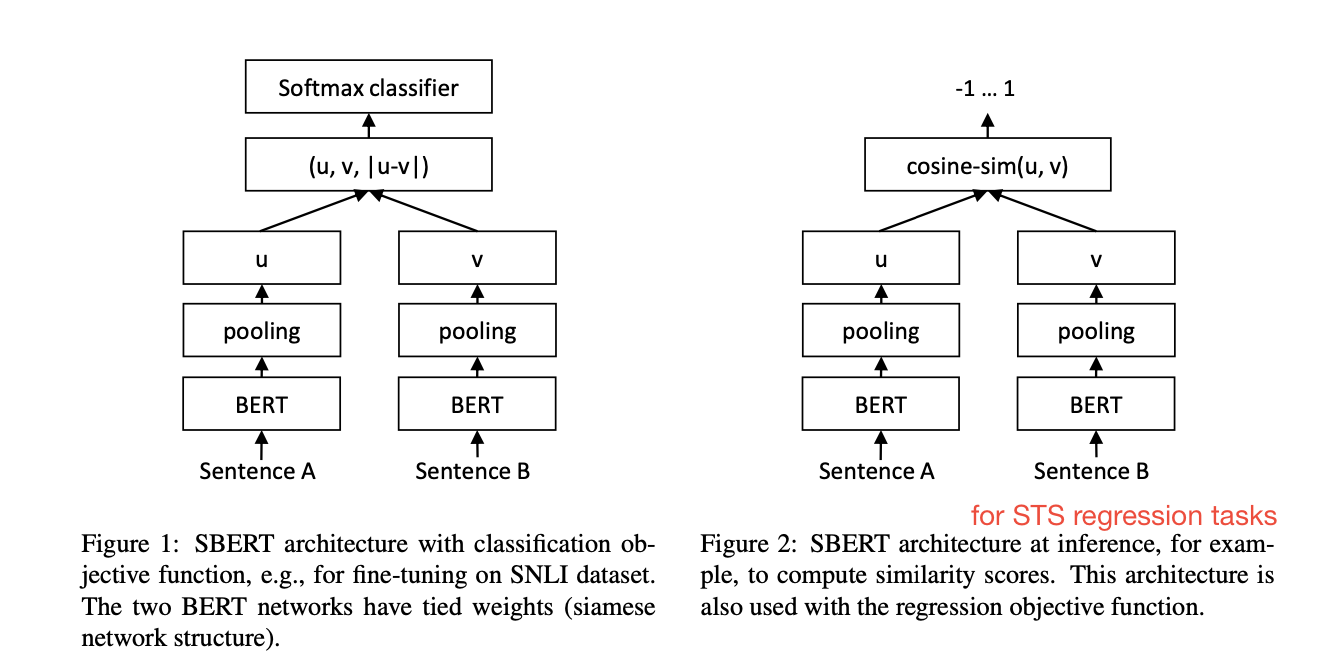
- Problem. Pair regression tasks are tasks where the input features consist of two pieces of text. For example, semantic textual similarity (STS). STS deals with how similar two pieces of texts are. This can take the form of assigning a score from 1 to 5.
E.g. “How are you?” and “How old are you?” are semantically different. “How old are you?” and “What is your age?” are semantically similar.
- Motivation.
- (Too slow) Finding the pair with highest similarity requires going through all possible combinations.
- (Too poor) Mapping each sentence to a latent space such that semantically similar sentences are close. For example, using BERT’s CLS embedding directly. However, this practice yields rather bad sentence embeddings, often worse than averaging GloVe embeddings.
- Key Idea. Use siamese network to derive semantically meaningful sentence embeddings.
- For classification tasks, the siamese network concatenates the vectors u, v, and - importantly - the norm between them. The norm establishes a notion of distance between the vectors (Figure 1). I suspect this helps the model refine the relationship between the vectors u and v.
- The model is also finetuned on NLI dataset, which naturally requires the model to understand relationship between two sentences.
- Very strong results on unsupervised STS and Senteval (which directly evaluates sentence embeddings of SBERT)
- Interestingly, it did not offer improvemenets for supervised STS using a regression objective function (Figure 2). The regression objecctive function defer from BERT in that BERT passes both sentences to the network and use a simple regression method for the output.
Coupled hierarchical transformer for stance-aware rumor verifification in social media conversations
This post will mainly cover hierarchical transformers.
Motivation.
- First, most previous studies employed BERT to obtain token-level representations for sentence or paragraph understanding, while the paper’s tasks (stance classification and rumour verification) primarily require sentence-level representa- tions for conversation thread understanding
How it works.
- Flatten all the posts in a conversation thread into a long sequence, and then decompose them evenly into multiple subthreads, each within the length constraint of BERT.
- Next, each subthread is encoded with BERT to capture the local interactions between posts within the subthread.
- A transformer layer is stacked on top of all the subthreads to capture the global interactions between posts in the whole conversation thread.
May
Back after ending my semester!
So Different Yet So Alike! Constrained Unsupervised Text Style Transfer
- Motivation. Unsupervised text style transfer often fail to maintain constraints. For example, translating “I really loved Murakami’s book” to “Loved the movie” does not correctly transfer the length, personal noun (“I”), and use a domain appropriate proper noun.
- To introduce constraints, this paper propose to introduce an explicit regularisation component in the latent space of a GAN-based seq2seq network through two complementary losses.
- The first loss is a contrastive loss that brings sentences that have similar constraints closer and pushes sentences that are dissimilar farther away.
- The second loss is a cooperative classification loss wherein they encourage the encoders and the critic to cooperatively reduce a classification loss (here, encoder and critic takes the same notion as in the GAN paper). Conceretly, a classifier predicts the different constraints of the sentences (produced by either the encoder and critic) and the binary cross entropy loss is reduced.
- Metrics. TST metrics are difficult to measure (e.g. semantic similarity, fluency, transfer accuracy). To circumvent this, they typically use classifiers as evaluation (e.g. fluency is based on RoBERTA trained on COLA to indicate if a sentence is linguistically acceptable).
Attention is not Explanation (Sarthak Jain, Byron C. Wallace, NAACL 2019)
- Assuming attention provides a faithful explanation for model predictions, we might expect the following properties to hold. (i) Attention weights should correlate with feature importance measures (e.g., gradient-based measures); (ii) Alternative (or counterfactual) attention weight configurations ought to yield corresponding changes in prediction (and if they do not then are equally plausible as explanations).
- We report that neither property is consistently observed by a BiLSTM with a standard attention mechanism in the context of text classification, question answering (QA), and Natural Language Inference (NLI) tasks.
[F]Generative Adversarial Nets (Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio)
- Deep learning primarily used in discriminative models. Deep generative models have had less of an impact, due to the difficulty of approximating many intractable probabilistic computations that arise in maximum likelihood estimation and related strategies, and due to difficulty of leveraging the benefits of piecewise linear units in the generative context.
- in this framework, the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution.
- The paper explores the special case when the generative model generates samples by passing random noise through a multilayer perceptron.
- The discriminative is also a MLP that outputs the probability that the training data (which consist of real examples and samples from G) came from the data rather than the generator.
- We train the discriminator to maximize the probability of assigning the correct label to both training examples and samples from G. We simultaneously train G to minimize $log(1-D(G(z)))$ (the converse of the discriminator’s objective).
- We can then sample from the generative model using forward propagation.
Disentangled Representation Learning for Non-Parallel Text Style Transfer (Vineet John, Lili Mou, Hareesh Bahuleyan, Olga Vechtomova, ACL2019)
- In this paper, they addressed the problem of disentangling the latent space of neural networks for text generation. Their model is built on an autoencoder that encodes a sentence to the latent space (vector representation) by learning to reconstruct the sentence itself. They would like the latent space to be disentangled with respect to different features, namely, style and content in their task.
Disentanglement is the problem of disentagling text into its content and attribute in the latent space, and apply generative modelling.
- They design a systematic set of auxiliary losses, enforcing the separation of style and content latent spaces.
- In particular, the multi-task loss operates on a latent space to ensure that the space does contain the information we wish to encode.
- The adversarial loss, on the contrary, minimizes the predictability of information that should not be contained in a given latent space.
Example with style-oriented loss. For multi-task loss for style, they build a softmax classifier on the style space to predict the style label. In the paper, the style space is sentiment classification, thus the style label is positive or negative. For adversarial loss for style, they train a separate classifier, called an adver- sary, that deliberately discriminates the style label based on the content vector c. Then, the encoder is trained to encode a content space from which its adversary cannot predict the style.
- Earlier works only consider style space and ignore the content space, as it is hard to formalize what “content” actually refers to. In their work, they propose to approximate content information by bag-of-words (BoW) features, where they focused on style-neutral, non-stop words.
Deep Learning for Text Style Transfer: A Survey (Di Jin, Zhijing Jin, Zhiting Hu, Olga Vechtomova, Rada Mihalcea, Computational Linguistics Journal 2022)
Goal. The goal of text style transfer (TST) is to automatically control the style attributes of text while preserving the content. Formally, we dnote the target utterance as $\mathbf{x’}$ and the target discourse style attribute as $a’$. TST aims to model $p(\mathbf{x}’|a, \mathbf{x})$, where $\mathbf{x}$ is a given text carrying a source attribute value $a$. For example,
- Source sentence $\mathbf{x}$: “Come and sit!”. Source attribute a: Informal.
- Target sentence $\mathbf{x’}$: “Please consider taking a seat”. Target attribute a’: Formal.
Ideally, parallel data is available, which allows us to apply standard seq2seq models directly. However, parallel data is often not available.
Methods (on non-parallel data)
- Disentanglement. Disentagles text into its content and attribute in the latent space, and apply generative modelling.
- Prototype Editing.
- Step 1: Detect attribute markeres of a in the input sentence $\mathbf{x}$, and delete them, resulting in a content-only sentence.
- Step 2: Retrieve candidate attribute markers carrying the desired attribute $a’$.
- Step 3: Infill the sentence by adding new attribute markers and make sure the generated sentence is fluent.
- Pseudo Data Construction. Construct pseudo-parallel data and train the model as if in a supervised way.
January
I’ll be taking a break with semester resuming! Hoping to finish my schooling years on a high 😎
Unsupervised Data Augmentation for Consistency Training(Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, Quoc V. Le, NeurIPS 2020) In a nutshell, consistency training methods simply regularize model predictions to be invariant to small noise applied to either input examples or hidden states. This framework makes sense intuitively because a good model should be robust to any small change in an input example or hidden states. This work observes that advanced data augmentation methods also work well with consistency training methods. They hence propose to substitute the traditional noise injection methods with high quality data augmentation methods in order to improve consistency training.
Controllable Neural Dialogue Summarization with Personal Named Entity Planning In dialogue summaries, perspective is important. For example, John and Tony’s perspective prioritises different summaries from the same source text.

However, a neural model with a general summarizing purpose may overlook information that is important to a specific person’s perspective. This paper introduces a controllable dialogue summarisation framework, in which module the generation process with personal named entity plannings. More specifically, as shown in the figure above, a set of personal named entities1 (in color) are extracted from the source dialogue, and used in a generation model as a conditional signal.
Coreference-Aware Dialogue Summarization (Zhengyuan Liu, Ke Shi, Nancy Chen. Coreference-Aware Dialogue Summarization, SIGDIAL 2021 (Best Paper Award)) This paper tackles the problem of text summarisation. Recent work focuses on single speaker content such as news articles but not dialogues. Dialogue summarisation is difficult because of 1) multiple speakers, 2) speaker role shifting and 3) ubiquitous referring expressions (e.g. speakers referring to themselves and each other). These challenges justify the usefulness of leveraging coreference information: when two or more expressions in a text refer to the same thing (e.g. Bill said he would come; the proper noun Bill and pronoun he refer to the same person). Large scale pretrained model are shown to implicitly model lower level linguistic knowledge such as PoS and syntactic structure. Since entities are linked to each other in coreference chains, this paper propose to add a graph neural layer that could characterize underlying coreference information structure, which can improve dialogue summarisation performance.
December
Vocabulary Learning via Optimal Transport for Neural Machine Translation(ACL2021, Best Paper award, Jingjing Xu, Hao Zhou, Chun Gan, Zaixiang Zheng, Lei Li) This paper considers the problem of vocabulary construction for neural machine translation and other NLP tasks. Current approaches primarily only consider frequency (entropy) but not size (e.g. BPE, Wordpiece tokenisation). However, there exist a tradeoff between the vocabulary entropy and the size: increase in vocabulary size decreases corpus entropy, but too many tokens cause token sparsity, which hurts model learning. Given this trade-off, this paper proposes to use the concept of Marginal Utility to balance it: in economics, marginal utility is used to balance the benefit and the cost and we use MUV to balance the entropy (benefit) and vocabulary size (cost). To maximize the marginal utility in tractable time complexity, they reformulated the optimisation objecitve into an optimal transport problem. Intuitively, the vocabularization process can be regarded as finding the optimal transport matrix from the character distribution to the vocabulary token distribution.
A Gentle Introduction to Graph Neural Networks Graph neural networks are commonly used for data which are naturally represented as graphs (.e.g molecules, social networks, citation networks). Tasks include: graph-level task (e.g. what the molecule smells like), node level task, edge-level task (image scene understanding). Solving this tasks will involve learning embeddings for graph attributes (e.g. nodes, edges, global). To make these learned embeddings aware of graph connectivity, one way is via message passing. Message passing works in three steps:
- For each node in the graph, gather all the neighboring node embeddings (or messages).
- Aggregate all messages via an aggregate function (like sum).
- All pooled messages are passed through an update function, usually a learned neural network
Using the Output Embedding to Improve Language Models(EACL2017, Ofir Press, Lior Wolf) This paper showed that the topmost weight matrix of the neural language models (i.e. layer right before the softmax) constitutes a valid word embedding layer. As such, we can tie both layers together - known as weight tying - so as to reduce the number of parameters.
Using “Annotator Rationales” to Improve Machine Learning for Text Categorization (NAACL 2007, Omar Zaidan, Jason Eisner, Christine Piatko) This paper proposes SVM training that can incorporate annotator rationales: subset of the input text that justify the task classification. Specifically, the paper constructs from positive examples $x_i$ positive “not-quite-as-positive” examples $v_{ij}$, which are obtained by masking out rationale substrings. In addition to the usual SVM constraint on positive examples that $w \cdot x_i \geq 1$, we also want (for each j) that $w \cdot x_i - w \cdot v_{ij} \geq \mu$, where $\mu \geq 0$ controls the size of the desired margin between original and contrast examples; that is, the margin of the original examples should ideally be much larger than the contrast examples.
Rationale-Augmented Convolutional Neural Networks for Text Classification (ACL2016, Ye Zhang, Iain Marshall, Byron C. Wallace) This paper augments CNNs with rationales for the task of text classifications. Specifically, it uses CNNs for sentence modelling. Thereafter, an estimator is trained to produce the probability if the given sentence is 1) positive rationale (when a rationale sentence appears in a positive document), 2) negative rationale, 3) neutral rationale (non-rationale sentences). Thereafter, a document level classifier makes a task classification based on the weighted sum of the sentence vectors, with the weights specified by the probability of the sentence being a rationale or not.
The authors also experimented with having only two sentence classes: rationales and non-rationales, but this did not perform as well as explicitly main- taining separate classes for rationales of different polarities.
Lightweight and Efficient Neural Natural Language Processing with Quaternion Networks (ACL2019, Yi Tay, Aston Zhang, Luu Anh Tuan, Jinfeng Rao, Shuai Zhang, Shuohang Wang, Jie Fu, Siu Cheung Hui) This paper explores computation in the Quarternion space (i.e. hypercomplex numbers) as an inductive bias. Specifically, quaternions $Q$ comprise of a real and three imaginary components in which interdependencies are naturally encoded during training (e.g. RGB scenes or 3D human poses) via the Hamilton product.
\[Q = r + x\mathbf{i} + y\mathbf{j} + z\mathbf{k}\]Hamilton products $\otimes$, which represents the multiplication of two quaternions $W$ and $Q$, have fewer degrees of freedom, enabling up to four times compression of model size. Specifically, $W \otimes Q$ can be expressed as:
\[\left[\begin{array}{cccc} W_{r} & -W_{x} & -W_{y} & -W_{z} \\ W_{x} & W_{r} & -W_{z} & W_{y} \\ W_{y} & W_{z} & W_{r} & -W_{x} \\ W_{z} & -W_{y} & W_{x} & W_{r} \end{array}\right]\left[\begin{array}{l} r \\ x \\ y \\ z \end{array}\right]\]Note that there are only 4 distinct parameter variable elements (4 degrees of freedom) in the weight matrix. In the real-space feed-forward, there will instead be 16 different parameter variables. In summary, Quaternion neural models model interactions between components via using hypercomplex numbers and provides efficiency via the Hamilton product, which have fewer degrees of freedom in comparison to matrix products in the real space.
Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks(ICLR 2019, Best Paper, Yikang Shen, Shawn Tan, Alessandro Sordoni, Aaron Courville) While the standard LSTM architecture allows different neurons to track information at different time scales, it does not have an explicit bias towards modeling a hierarchy of constituents. This paper proposes to add such an inductive bias by ordering the neurons; a vector of master input and forget gates ensures that when a given neuron is updated, all the neurons that follow it in the ordering are also updated.
When Attention Meets Fast Recurrence: Training Language Models with Reduced Compute (EMNLP 2021 Outstanding Paper, Tao Lei) This paper combines attention with recurrent neural network that achieves strong computational efficiency; the simple recurrent unit is efficient because 1) it combines the three matrix multiplications across all time steps as a single multiplication and 2) implements element wise operations as a single CUDA kernel to accelerate computation.
Archive
Few-shot Conformal Prediction with Auxiliary Tasks (ICML 2021, Adam Fisch, Tal Schuster, Tommi Jaakkola, Regina Barzilay) To circumvent the problem of prediction sets becoming too large when limited data is available for training, this paper casts conformal prediction as a meta-learning paradigm over exchangeable collections of auxiliary tasks.
Rethinking Positional Encoding in Language Pre-training (Guolin Ke, Di He, Tie-Yan Liu) This paper 1) unties the correlations between positional and word embeddings by computing them separately with different parameterizations before adding them (as opposed to adding before computing) and 2) unties [CLS] symbol from other positions, making it easier to capture information from all positions (as opposed to being biased to the first several words if we apply relative positional encoding)