
Suppose that every device takes in a batch of tensors where the tensors across devices are of different sizes, will 3D parallelism still work?
Published:
As I’m learning more about 3D parallelism, I wonder - suppose that every device takes in a batch of tensors where the tensors across devices are of different sizes, will 3D parallelism still work? Turns out, it works for data and pipeline parallelism, but tensor parallelism will need some work.
For data parallelism, every device sees a different partition of the data, thus even if the tensors are of different sizes across devices, it’s the same per device, so no shape issues here.
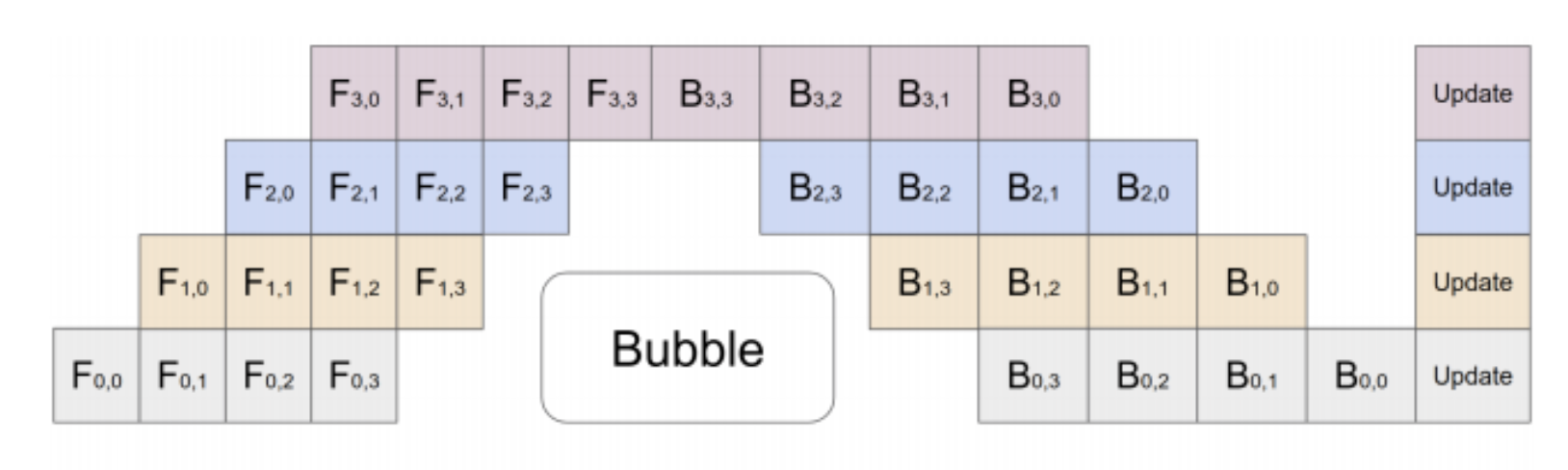
For pipeline parallelism, using the notations of the diagram below, device $F_{0,i}$ takes in the batched tensors, device $F_{1,i}$ computes the output from $F_{0,i}$, device $F_{2,i}$ computes the output from device $F_{1, i}$ and so on. So notice that from every device’s perspective, it’s still taking in a batch of tensors of the same size, thus no shape issues again.
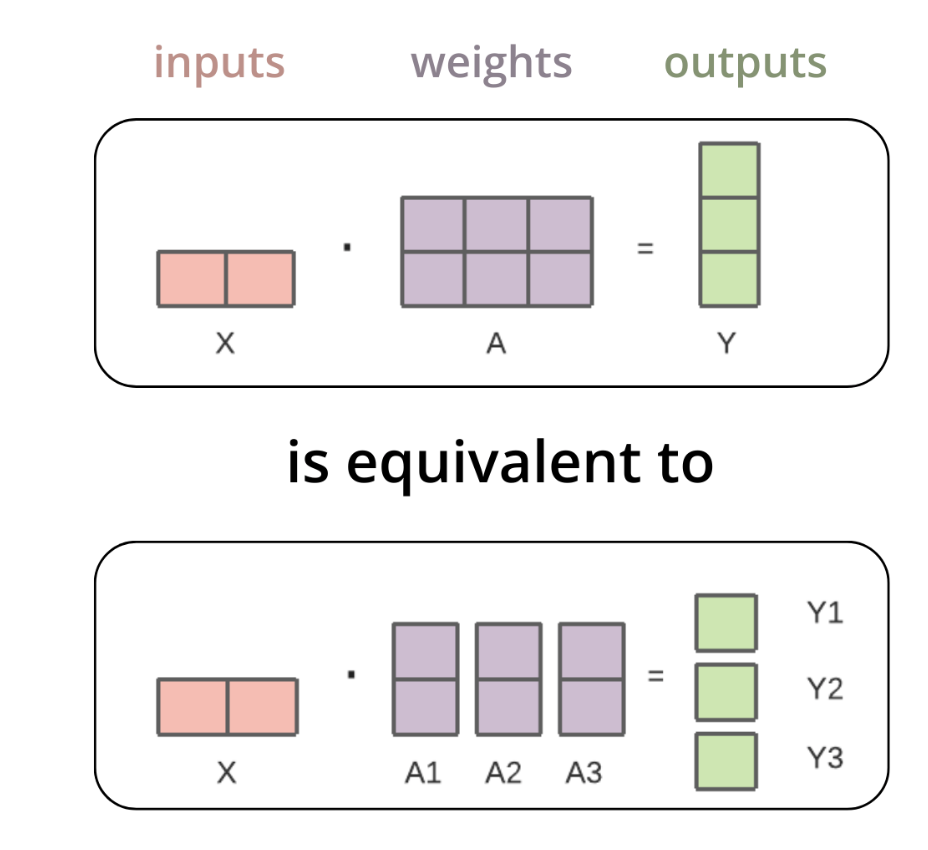
For tensor parallelism, using the notations of the diagram below, tensors $A_1$, $A_2$, $A_3$ will be loaded in separate devices in order to compute tensor $Y$. To do this parallelisation, typically a source device needs to broadcast the source tensor (i.e. $A$) to the separate devices of the same group.
Using Megatron-LM’s code as reference,
def _broadcast(item):
if item is not None:
torch.distributed.broadcast(item, mpu.get_tensor_model_parallel_src_rank(), group=mpu.get_tensor_model_parallel_group())
if mpu.get_tensor_model_parallel_rank() == 0:
...
batch = {
'tokens': data["tokens"].cuda(non_blocking = True),
...
}
_broadcast(batch['tokens'])
else:
...
tokens=torch.empty((args.micro_batch_size,args.seq_length), dtype = torch.int64 , device = torch.cuda.current_device())
_broadcast(tokens)
Notice how TP rank 0’s tensor takes in the input tensors while the other devices initialize an empty tensor. TP rank 0 will then broadcast the input tensor to the other devices. When we do packing, we’ll know the size of each tensor in advance, thus we can initialize the empty tensors with this known size. However when source tensor is of size is only known during runtime, we need to first obtain the size from TP rank 0 before initializing the tensor.
As my wise senior once said, the code is the only source of truth. So I simply randomized each batch’s length within the code. DP and PP works (i.e. code compiles and training loss decreases), and TP breaks.
def _broadcast(item):
if item is not None:
torch.distributed.broadcast(item, mpu.get_tensor_model_parallel_src_rank(), group=mpu.get_tensor_model_parallel_group())
if mpu.get_tensor_model_parallel_rank() == 0:
...
batch = {
'tokens': data["tokens"].cuda(non_blocking = True),
...
}
stubbed_length = random.randint(50,args.seq_length)
batch['tokens'] = batch['tokens'][:, stubbed_length]
_broadcast(batch['tokens'])
else:
...
tokens=torch.empty((args.micro_batch_size,args.seq_length), dtype = torch.int64 , device = torch.cuda.current_device())
_broadcast(tokens)