
Given the same compute budget, which is better: parameter efficient finetuning (PEFT) or full finetuning?
Published:
Motivation
If we are allowed to train till convergence, we know that full finetuning is better than parameter efficient finetuning (PEFT). But what if we have a fixed compute budget? Given a fixed budget, PEFT can go through significantly more tokens. Will full finetuning still be better than PEFT?
For my research problem, it turns out full finetuning is still better than PEFT.
Experiment Setup
For context, my research problem is to adapt english LLMs to other languages. I finetuned llama-7B on roots_* datasets (datasets used to train BLOOM) and open subtitles. For PEFT, I used LoRA and additionally trained the embedding and LM head.
Results
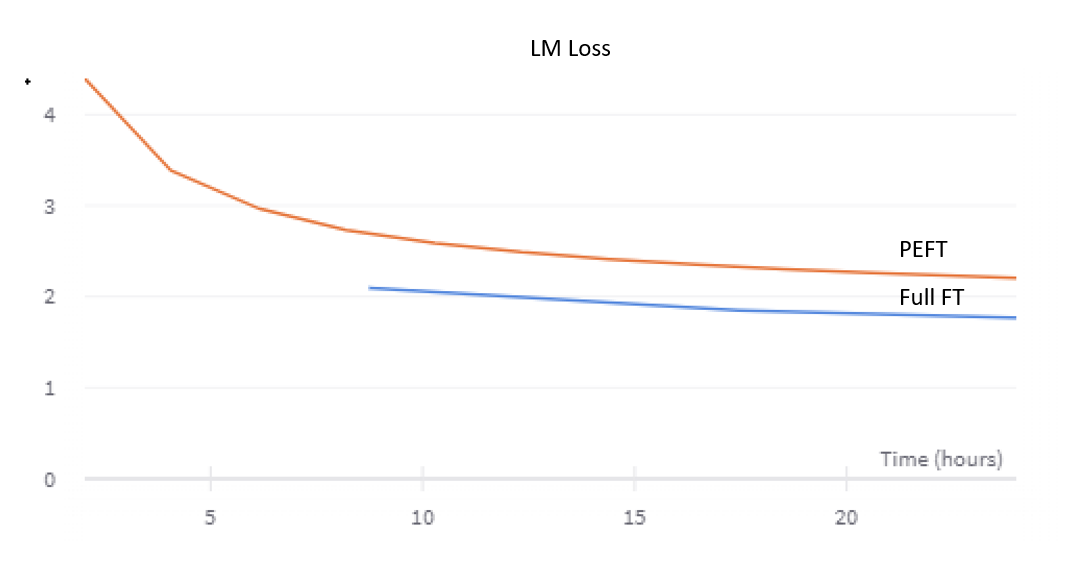
Here, we can see that full finetuning (blue) achieves a better loss than PEFT (orange) given the same compute budget! Seems like finetuning can - ironically - be more efficient that PEFT. Interesting!
From my colleagues’ experiments, turns out PEFT only speeds up 25% compared to finetuning despite training <1% of parameters.